Once upon a time there was a t-shirt that read,
“The computer is the computer.
The network is the network.
Sorry about the confusion.”
This slogan was a geeky rebuttal to “The network is the computer,” a tagline attributed to Sun Microsystems’ fifth employee, John Gage.
Whether Gage’s famous line actually had any influence on the architecture and evolution of distributed systems, or whether it was simply an observation, the view that some of us have kept to ourselves is that perhaps the emphasis on the network has been misguided. If programmers didn’t have to concern themselves so much with the nitty-gritty of network protocols, writing software for distributed applications would be easier.
Most distributed applications operate on the same principles. Application processes use remote procedure calls (RPCs) to databases running on separate systems, which are connected by a LAN, or in today’s cloud environments, even the Internet.
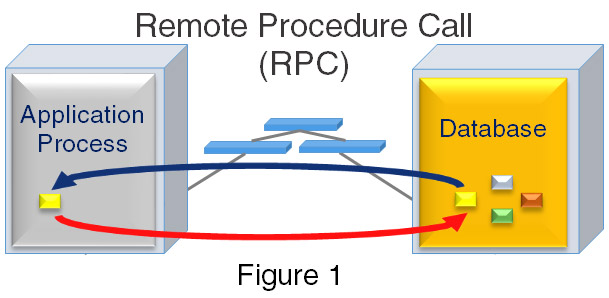
The theory is simple enough, but in practice, programmers have to deal with all kinds of details that clutter up the design and add complexity to writing and debugging applications. This not only adds technical complexity, but it affects productivity and accuracy, which can have consequences for the company’s bottom line.
In order to get access to the data, the applications programmer has to include IPC (inter-process communication), TCP/IP sockets, message queuing, and so on. In a high-availability (HA) system, even more complexity typically has to be written into the application software, to handle failover to a redundant instance.
Complexity isn’t the only issue with distributed systems: in today’s demanding applications, milliseconds, and even microseconds can be precious. In the diagram above, the round-trip delay of each RPC consists of several steps, including:
- The time in the TCP/IP protocol stack for request
- The network traverse time
- The time in the DBMS server’s stack
- The time in the DBMS server’s stack to send the data back
- The network transit time, and
- The application server’s protocol stack time to receive the data.
It is important to note that there are different definitions of latency for different purposes. Somebody who focuses on the network will often refer to network latency, based on how long it takes the first bit of a data item to cross the network one way. While this is certainly one valid measure of network performance, from the view of an application owner what it important is the response time delay attributable to the networking components of the total system.
From the application owner’s perspective, data access across a bleeding-edge ultra-low latency one-hop network, with the fastest available network interfaces, and no network congestion, the response time of accessing data as shown in Figure 1 is going to be tens of microseconds worse than accessing data on the local server. More typically, even on a lightly-loaded network, the extra latency of an RPC call can be hundreds of microseconds to milliseconds more than the memory access speeds.
OptumSoft figured out a better way.
Instead of using an RPC every time you need to access data, we let you move the data to where each of the application processes runs. The TACC runtime system takes care of the complexity around where the data resides and makes sure it is consistent among all of the processes that are using the data.
Doing this has not been easy. It took decades of experience, and multiple iterations, to get it right. However, the benefits in reduced program complexity, performance, and reliability are dramatic.
We will explore the details of what it does and how it works in the next post.
Comments are closed